In our recent official release (v24.1), we added support for Firestore database in our list of KingswaySoft NoSQL components within our SSIS Productivity Pack. Firestore is a powerful document based NoSQL database that handles data in the form of collections and documents. It has an intuitive data model with an easy-to-use UI, is highly scalable and flexible, and includes powerful querying and indexing features. Typically, NoSQL databases are popular in terms of their broad functionality compared to traditional relational database systems. Firestore database is a good choice for managing large-scale real-time updates. Some major advantages of using Firestore are:
- Scalable for large data volume
- Flexible data model
- Document oriented storage
- Structured, semi-structured and unstructured data handling
The challenge, however, would be that, in an integration scenario, you would need this data in a structured or tabular format, which can then be used to write to a target instance or to perform any transformations. In this blog post, we will go over our KingswaySoft Firestore Source component to demonstrate how to read from a set of complex documents within a Firestore collection and output this data in a structured format.
Familiarizing Firestore Studio
Within your Google Cloud console, you can open Firestore Studio to easily access your Firestore project. If you wish to create a new collection, click on "Start Collection" as shown below and enter the required details.
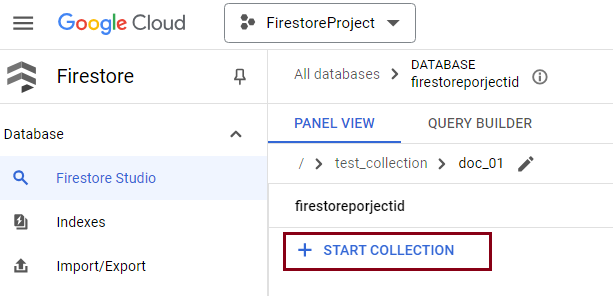
The Collection ID can be any name, and there is a field to add your first document to it. The Document ID is automatically generated, and you can choose to either use it as is or provide a different value that you know is unique. In our example, we used the Firestore-generated document ID for each document.
We created a few documents in a semi-structured format, with fields being unique and some repeating.
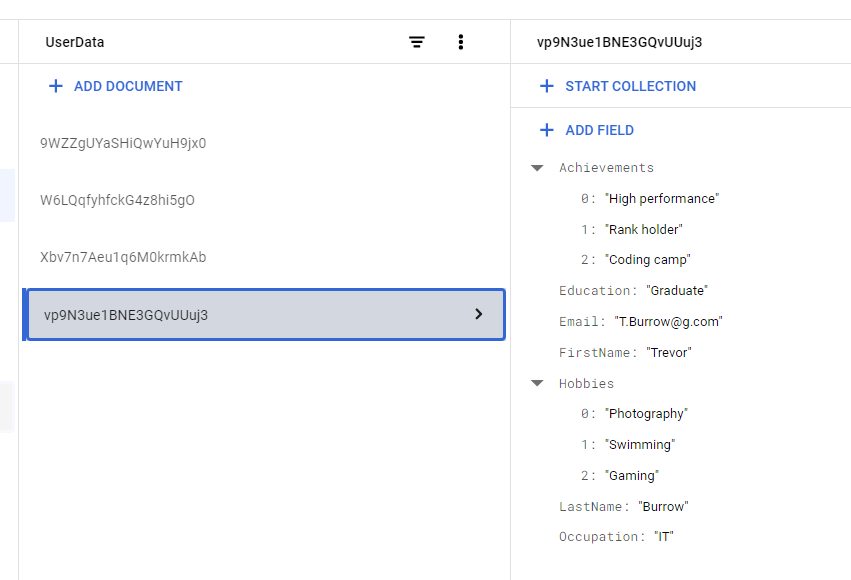
(Document 1)
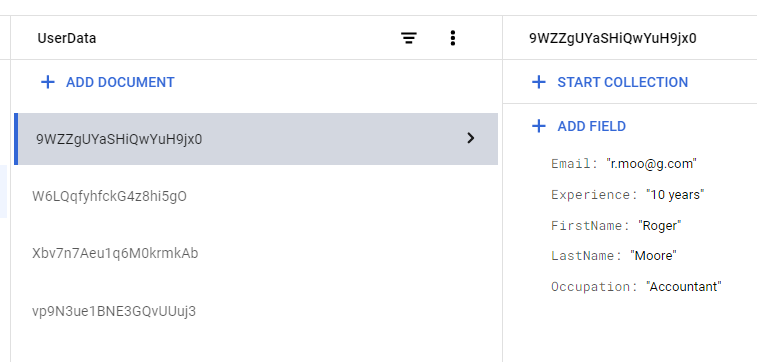
(Document 2)
Please note that in a real-world scenario, these documents would be received from a massive process, which collects and stores data in your collection. The above documents we have created are just an example to showcase a small set of data in such a structure. We could proceed to our SSIS package to set up the Firestore connection manager and the Source component.
Firestore connection and component configuration
KingswaySoft Firestore connection manager offers two ways to connect to the instance. One would be to use an Authorization code, which is OAuth-based to enter your Client ID and Client Secret, which are generated from your OAuth App in Google Console, to create a token file that can be used in the connection manager. The second option would be to use a Service Account that would allow you to work with a JSON key file or a P12 key with a certificate and a thumbprint.
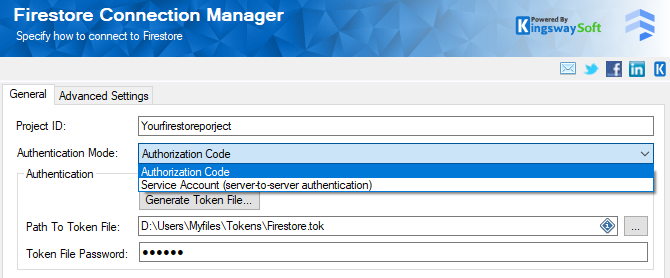
More details on each parameter involved in the connection manager can be found in our Online Help Manual.
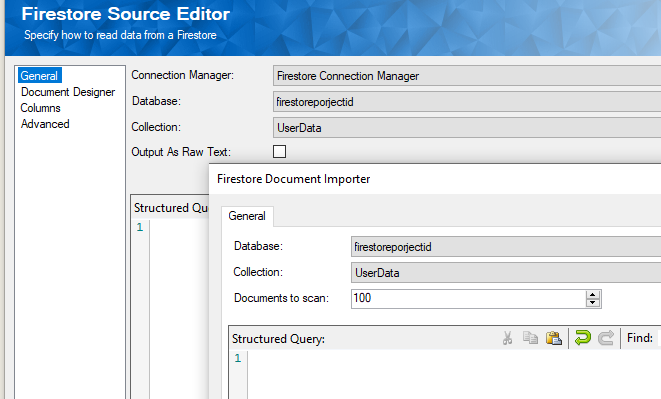
Once the connection manager is configured, we move on to the Firestore Source component, in which the Database and the Collection can be chosen from the available list. The new collection that was created will be discovered when the drop-down is clicked. When chosen, it gives you the option to import the document, and this can be done based on the collection documents within the collection. In the field called "Documents to Scan", enter the number of documents that you would like to be scanned in order to gather the document metadata information so that the source component can populate the document design. The higher the number, the more documents will be retrieved and scanned which can help improve the accuracy of the document designer, thereby reducing any potential metadata or data loss.
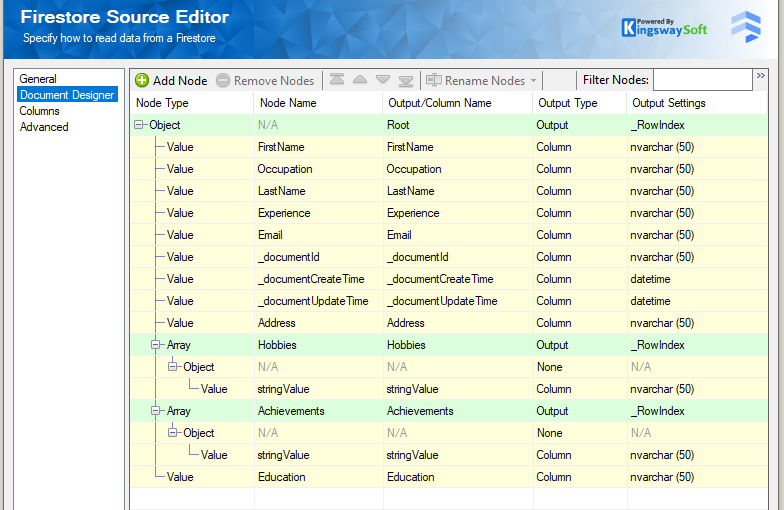
Once imported, navigate to the Document Designer page and you will see the design imported as shown below. When the document is read from Firestore, the source component breaks down the complex structures in the document by converting them into flattened column data for easy consumption and processing in the SSIS ETL pipeline.
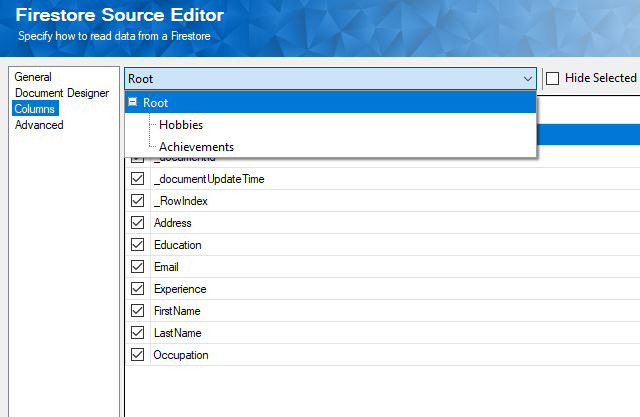
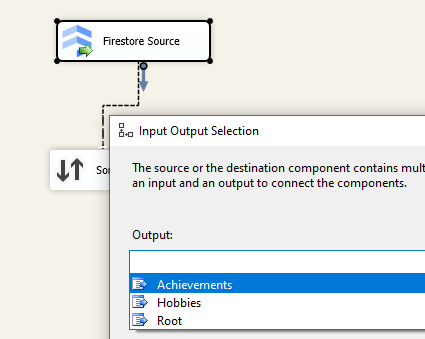
On the Columns page, you will see the option to select different outputs. In our case, we have Root, Hobbies, and Achievements—three different outputs in total—with Root as the parent and the latter two as child outputs.
After saving and closing the Firestore source component, we can connect it to downstream pipeline components, such as a destination or transformation component, for further processing and writing. Because the Firestore Source component has multiple output objects, you will be prompted to select one of the outputs when connecting to the downstream pipeline component, as shown below.
It is worth noting that when working with a JSON or XML document, you often encounter situations where you need to handle a hierarchical document. In such cases, it must be broken down into more granular objects, which translates into multiple outputs—this is precisely what occurs in our Firestore source component. This is fairly common. However, if you ever need to flatten these together again to obtain the entire result set in one output in tabular format, you can easily use the Merge Join components to achieve this. For your reference, our Firestore Source component provides two fields called _RowIndex and _ParentKeyField respectively in those outputs. The values from those fields can be used to build the relationship by merging the data in a flattened format to generate one output again. In order to use the Merge Join component, you would typically need to add a Sort component beforehand to have the data prepared for the joining. The following data flow shows how this can be achieved.
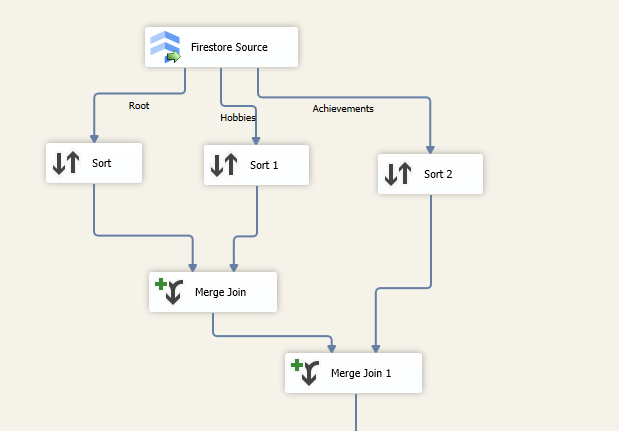
For further details on the parent and child relationship, you can refer to this Blog Post, which covers some of the details on how the parent-child outputs can be linked together using the rowindex and the parentkeyfield columns.
Conclusion
As seen in the above example, KingswaySoft Firestore components can be used to efficiently parse through semi or unstructured data documents from your Firestore database collections, to get them out in a useful format. The document designer can also be tweaked in order to manipulate how the data is output, thereby giving you the flexibility to work with the data as required.
We hope this has helped!