In your ETL integration development, you might run into a situation where you need to obtain some information from a JSON or XML file served by an HTTP service endpoint via either SOAP or REST framework. Creating a solution to achieve this can be challenging without a proper tool. If you are a data flow specialist with heavy data flow engineering experience, particularly if you have worked with our SSIS Integration Toolkit product family, including SSIS Productivity Pack, you would most likely start a new data flow task and put in a dummy source component (such as the Data Spawner component). Then, you would send the dummy source component to an HTTP requestor component to download the file from the service endpoint before sending the data to a JSON Extract or XML Extract component, in order to extract the required pieces of information. Later on, you would write such extracted information to an SSIS variable using our Premium Derived Column component, so that the information stored in the SSIS variables can be used at a later stage of the integration process. As you can already see, this entire solution can be cumbersome to implement due to the heavy use of ETL data processes while the requirement is simply extracting a few pieces of information from a few XML or JSON nodes.
With the above in mind, we want to show you a much more simplified solution in this blog post. Our focus is to avoid the heavy use of data flow process whenever possible, particularly if our purpose is to simply extract a few XML or JSON node values from a known service endpoint. Having said that, we will be showing a solution that leverages the following three components - note that the third one is optional, and is only used for verification purposes.
The overall design of our flow would look as shown below. Note that, you would be replacing the JSON Extract Task with the XML Extract Task if your requirement is to read data from XML structures. We will be going through each of the tasks separately, on its design and configuration. It is worth mentioning that the last data flow task "Variable Value Validation" is just for data verification purposes, it is most likely not needed in your real-life business use case.
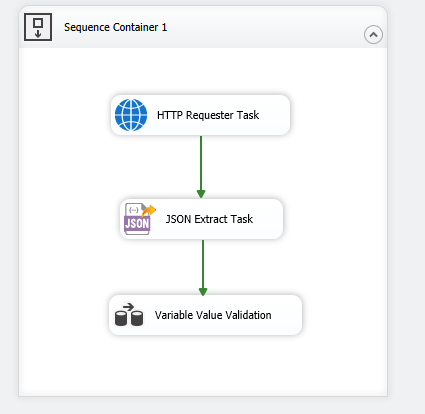
Now, let's dig deeper into the specific design aspects.
HTTP Requester Task for File Download
First, we use the HTTP Requester Task to download files or file contents from the service endpoint. Drag and drop the task from the control flow SSIS toolbox, open it, and select an already configured HTTP connection manager from the list of available connections (click here to learn more about the connection manager). Then, enter the other details such as relative path, HTTP method, query string parameters, request headers, etc., as required. Note that, in the screenshot below, we have provided a relative path for downloads and a couple of query string parameters to request precisely the file according to our business requirements. After this, in the Response Body Output section, choose Output to Variable. In doing so, the component would download the file when executed and save the file content to the specified SSIS variable (@User::JSONVar) that will be used later in the ETL process.

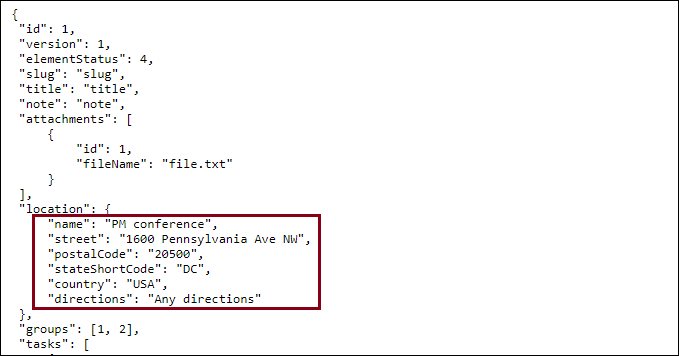
Now, with the file content saved in the SSIS variable, we just need to properly read this variable and extract the information from the document accordingly. Below is part of the JSON file content we intend to download, with the highlighted portions indicating what we need to parse out. As you can see, the portion of the nodes we wish to read out is straightforward and contains only a few pieces of information. To emphasize the point mentioned in the earlier section, in such cases, it is easier to achieve this purpose using a control flow task if available, which makes the solution much simpler.
Now, we move on to the next section.
JSON Extract to Read and Parse JSON Structure
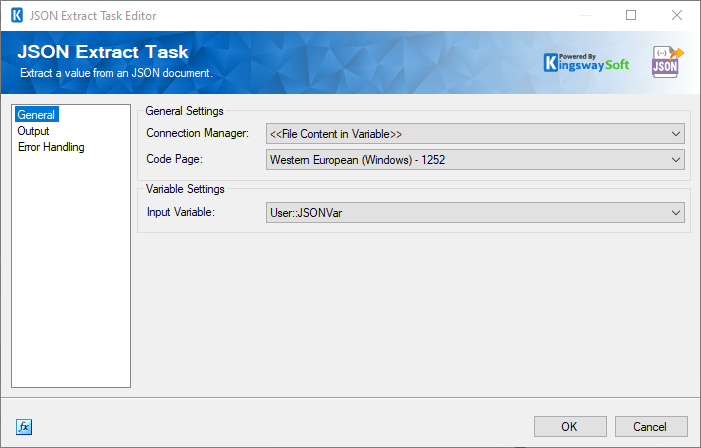
We would now drag and drop a new JSON Extract Task to the ETL process, and connect it right after the HTTP Requester Task created earlier. To complete the configuration, we need to open the JSON Extract task. Here, we choose the connection manager as File Content in Variable and then select the variable @User::JSONVar. At runtime, this variable will have the file content downloaded in our previous task.
Once done, switch to the Output page, and enter the JPath for the node (which can be identified easily using any online JPath finder tools). Then, for each document node required, you would assign the node content to a new SSIS variable. If you do not have a variable created yet, we provide an option to create one on the go at design time, by clicking on the "New Variable" option.
The Output page of the JSON Extract Task will look as shown below once you have assigned all the JPaths to their respective variables. Note that the JSON Extract Task also offers an option called Error On Not Found which can be enabled if required, to handle the paths/values that do not exist in the source file as an error-handling strategy. This can be accomplished on the Error Handling page of the task. Please check out our Online Help Manual for more details on this.
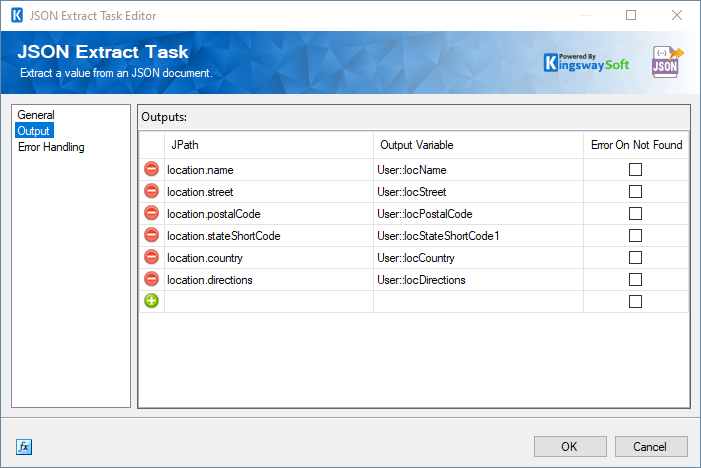
Now, when you run the package or the container, the output variables will get assigned the respective values from the JPaths, and these variables can be used at a later stage in your integration.
At this point, our development around the file content extraction is very much done. We can technically wrap up the blog post. Before we do so, we will add one more section to show you how to validate the above process design. While doing so, you might be able to get some inspiration on how the variable can be properly used as well.
Variable Value Validation
As we just mentioned above, this section is entirely optional. We are just showing you how to quickly verify the values retrieved by the JSON Extract Task - for the purpose of demonstration and illustration.
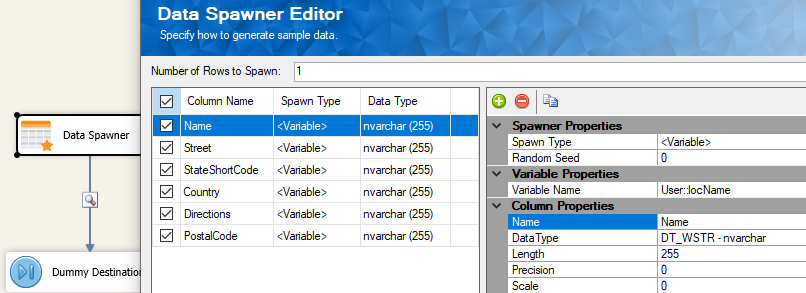
For demonstration, let us assign the variables as column values using a Data Spawner component, as shown below. Then, we use a Dummy Destination component to terminate the data flow, and a data viewer enabled on the data flow path.
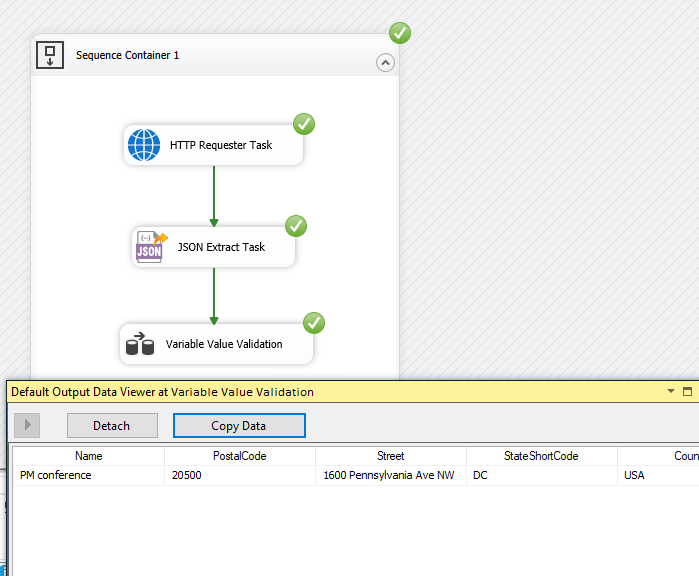
Once you have it all set up, execute the package/container that holds the tasks, and you should get the output as shown below. You will notice that the node values from JSON would be parsed out to variables, which are then read as column values per our design.
Conclusion
As seen above, you can easily work with our JSON Extract Task to read and parse node values within the control flow, without having to go into more complex data flow designs. This proves to be simpler in terms of design while giving you the capability to extract just the required set of values from your JSON structure. The JSON Extract Task also eliminates the need for a JSON document design to identify the nodes and instead relies on a JPath that you are familiar with. It is worth mentioning that our XML Extract Task works in a very similar fashion if your requirement is to extract from an XML file served by an HTTP service endpoint or a local file.
We hope this has helped!