Using the CRM/Dataverse/CDS Destination Component
The Dynamics CRM/Dataverse/CDS Destination components share the same UI, they work as the SSIS data flow components that can be used to write data to a Dataverse/CDS instance or Microsoft Dynamics 365 CE/CRM server. The components support a total of 11 writing actions including Create, Update, Delete, Upsert, Convert, Merge, Send, BulkDelete, ExecuteWorkflowAction, CalculateRollup, and ReviseQuote for writing or processing purposes.
The CRM/Dataverse/CDS Destination Component includes the following three pages to configure how you want to write data to CDS/Dataverse or a Microsoft Dynamics 365 CE/CRM server:
General Page
The General page of the CRM/Dataverse/CDS Destination Component allows you to specify general settings for the Dynamics CRM/Dataverse/CDS destination component.
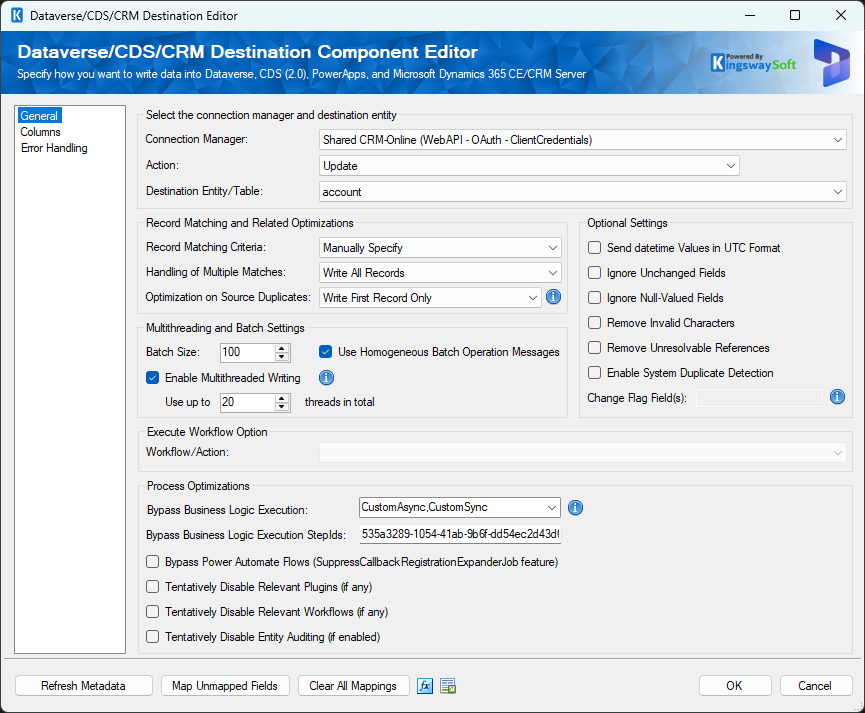
- Connection Manager
-
The Dynamics CRM/Dataverse/CDS destination component requires a CRM/Dataverse/CDS connection in order to connect with the CDS instance or Microsoft Dynamics 365 CE/CRM server for writing or processing purposes. The Connection Manager option will show all DynamicsCRM or Dataverse/CDS (KingswaySoft) connection managers that have been created in the current SSIS package or project.
- Action
-
The Action option allows you to specify how data should be written to the CDS instance or Microsoft Dynamics 365 CE/CRM server. The following actions are available:
- Create: Create new record(s) in CRM/Dataverse/CDS
- Update: Update existing record(s) in CRM/Dataverse/CDS
- Delete: Delete record(s) from CRM/Dataverse/CDS
- Upsert: Update any existing record(s) in CRM/Dataverse/CDS if matching can be found, otherwise create a new record with the information from the upstream pipeline components.
-
Convert: Convert a CRM/Dataverse/CDS record. The following are the supported entities:
- Lead: Qualify a lead by converting it to CRM/Dataverse/CDS account, contact and opportunity records
- Opportunity: Convert an opportunity record to a quote
- Quote: Convert a quote to a salesorder
- Salesorder: Convert a salesorder to an invoice
- Team (applicable to CDS, CRM 2013 or later): Convert an owner team to an access team
-
Merge: The Merge action takes two CRM/Dataverse/CDS records as its input and performs a CRM/Dataverse/CDS merge action on them by retaining one of them while retiring another one.
The Merge action is only possible with the following CRM/Dataverse/CDS entities:- account
- contact
- lead
- incident
- targetid: the record that you would like to retain.
- subordinateid: the record that is going to be retired, in which case, the record itself will be deactivated and all child records will be re-parented underneath the retained record which is specified by the targetid input column.
- CoalesceNonEmptyValues: specify a Boolean value to determine whether to coalesce a non-empty value during the Merge operation. When the input value for this field is true, the destination component will try to coalesce non-empty values during the Merge operation. For example, when this is set to true, and if the subordinate record has a value for a particular field, but the target record does not have a value (usually in the format of NULL), then the value from the subordinate record will be copied over to the target entity record. The default behavior is false if this field is not mapped.
- PerformParentingChecks: specify a Boolean value to determine whether a parenting check is needed during the Merge operation. Set to Ture to check if the parent information is different for the two entity records, otherwise, False.
- ExecuteWorkflowAction: Execute CRM/Dataverse/CDS workflow or custom action against all the data flow records passed to the destination component, which can be used to execute workflow or custom action against a large number of records with ease. This action used to be called ExecuteWorkflow before the v20.2 release.
- Send (since v9.0): Send CRM/Dataverse/CDS email(s) for each incoming record against the specified connection.
- BulkDelete (since v9.1): Submit a bulk delete job that deletes selected records in bulk. This job runs asynchronously in the background without blocking other activities.
- CalculateRollUpField (since v11.1): This option allows you to force the calculation of CRM/Dataverse/CDS rollup fields.
- ReviseQuote (since v20.1): This option can be used to revise the quote.
- Destination Entity
-
The Destination Entity option allows you to specify which CRM/Dataverse/CDS entity to write data to. When an option is selected, the SSIS Integration Toolkit will retrieve a list of all available CRM/Dataverse/CDS entities from the selected connection. Note that the list will only include the entities that the connection user has the proper write privileges.
Note: You may select an N:N (many-to-many) CRM/Dataverse/CDS relationship entity as the Destination Entity, in which case you use the Create action to create an association between two CRM/Dataverse/CDS records, and use the Delete to disassociate two records. When the Upsert action is used for an N:N relationship entity, the component will first check if an association already exists in the system for the concerning records. It will skip the input if such an association already exists, or otherwise, it will create a new association if no such relationship exists in the system between the two CRM/Dataverse/CDS records.
Note: There is a CRM/Dataverse/CDS entity called accessteammember, this is not an actual CRM/Dataverse/CDS entity. It is an artificial entity that is created to help facilitate adding/removing users to a CRM/Dataverse/CDS access team. This entity is not available when you are working with Dynamics CRM server 2011 or lower since the access team feature was only introduced in Dynamics CRM 2013. Further details about how to use entity are covered later in this document.
- Record Matching Criteria
-
The Record Matching Criteria option used to be called Upsert/Update Matching Criteria (v20.1 or earlier), which allows you to specify how Update or Upsert actions work in determining how to identify the record in the target CRM/Dataverse/CDS system for writing purposes. In the case when the Update action is used, this option is used to specify how to find the matched records in the CRM/Dataverse/CDS system to perform an update. When this is used for the Upsert action, it will be used to perform the lookup of the target system in order to determine whether it is a new record to be created or an existing record to be updated. The component supports the following four matching options when the Update or Upsert action is selected.
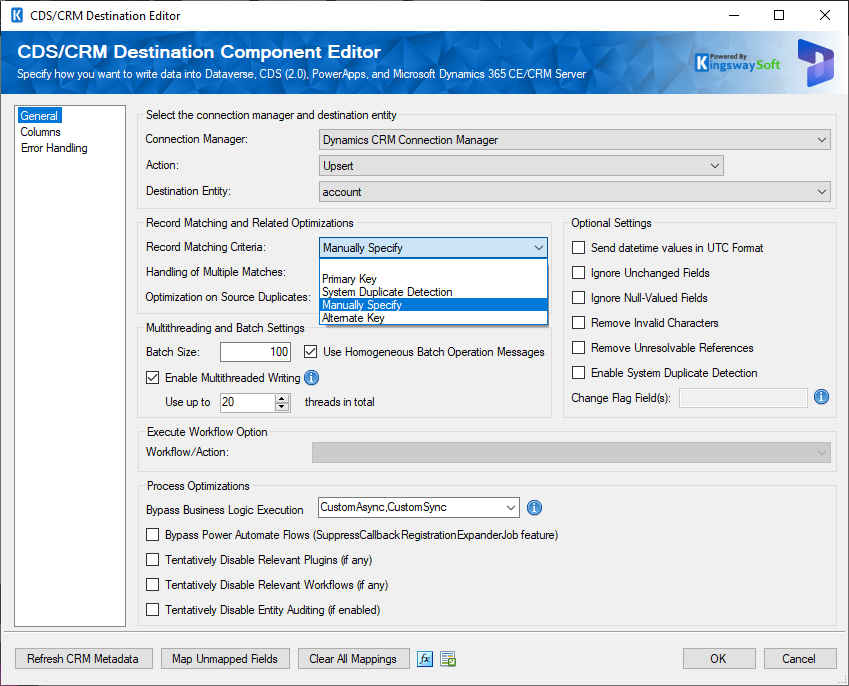
- Primary Key: The Primary Key option matches CRM/Dataverse/CDS records based on the input value that is mapped to the destination entity's primary key field.
- System Duplicate Detection: This option used to be called CRM Duplicate Detection (v20.1 or earlier), it uses CRM/Dataverse/CDS duplicate detection rules defined in the system to match those incoming records against the target system for matching purposes. We generally don't recommend using this option due to the restrictions associated with the CRM/Dataverse/CDS duplicate detection feature. Another reason to avoid this option is that system duplicate detection rules can be disabled in the system silently due to different reasons. We generally recommend the Manually Specify or Alternate Key options instead which will be discussed below and they offer a more robust matching strategy without those mentioned problems.
- Manually Specify: The Manually Specify option allows you to choose one or more CRM/Dataverse/CDS fields to be used as the matching key(s) in order to locate or identify the matching record(s) in the target CRM/Dataverse/CDS system. When the Manually Specify option is selected, the grid in the Columns page will show a checkbox in its first column which you can check or uncheck to indicate that the field is selected as a matching key. You will at least specify one such key field on the Columns page when this option is selected.
- Alternate Key: The Alternate Key option uses a system-defined Alternate Key as the matching option in locating or identifying the records in the target system for the writing purpose. When this option is selected, an Alternate Key option will have to be specified next.
- Primary Key: The Primary Key option matches CRM/Dataverse/CDS records based on the input value that is mapped to the destination entity's primary key field.
- Handling Multiple Matches
-
It is possible that the Upsert action could find multiple matches in the target CRM/Dataverse/CDS system when CRM Duplicate Detection or Manually Specified options are used. The Handling of Multiple Matches option allows you to specify what action will be taken when such multiple matches are found. There are four options available.
- Update All: This is the default behavior of the version prior to v3.0
- Update One: The component will only update the first matching record
- Ignore: The source row will be ignored when multiple matches are found
- Raise an error: An exception will be reported when multiple matches are found
- Optimization on Source Duplicates
-
This option is designed to work with the situation when your source data contains duplicates based on the Upsert/Update key field(s). There are 3 options available, and each of them comes with its own pros and cons.
- No Optimization: This option is the recommended option when there are NO duplicates from the source system. When the option is used in the situation that there are duplicates from the source system, the Upsert action could end up creating duplicate records in the target system if duplicates are received in the same batch.
- Write First Record Only: This option is recommended when there are duplicate records from the source system but you want to write only the first record. When using this option, all the duplicate records after the first one will be skipped. They are available in the "Skipped Rows" output if needed. Note that this option involves the use of a buffer-level global cache, it will increase memory usage when used.
- Write All with no Duplicate Creation: This option would write all incoming rows to the target system, with the first record being created if it happens to be a new record, all subsequent records will be updated. This provides the best fidelity to the change history of the source system if needed. However, it is important to note the update sequence may not be in the exact same order as the incoming rows when multi-threaded writing is enabled. To achieve 100% fidelity, multi-threaded writing will need to be disabled. This option also involves the use of a buffer-level global cache, which can increase memory usage during the process. Note that when this option is used for the Update action, it will behave the same as the "No Optimization" option, and there will be no memory usage involved.
- Remove Unresolvable References
-
The Remove Unresolvable References option specifies how to handle CRM/Dataverse/CDS lookup fields when reference records are not available. When this option is checked, if a CRM/Dataverse/CDS lookup field refers to a CRM/Dataverse/CDS record that does not exist in the system, the CRM/Dataverse/CDS lookup field will be removed before the data is written to the CRM/Dataverse/CDS system.
Note: We do not typically recommend using this option, since it will remain silent to any broken lookup references.
Note: The Remove Unresolvable References option is not available when the Action is Delete.
- Enable System Duplicate Detection
-
The Enable System Duplicate Detection option specifies whether CRM/CDS/Dataverse duplicate detection rules should be fired when writing data to CDS/Dataverse, or Microsoft Dynamics 365 CE/CRM.
Note: The Enable System Duplicate Detection option is not available when the Action is Delete.
Note: In order for the System Duplicate Detection option to take effect, you must set up proper duplicate detection rules for the target CRM/Dataverse/CDS entity in your system. You must also enable duplicate detection, which is a system-wide configuration setting available in Settings -> Data Management -> Duplicate Detection Settings.
Note: There is a special behavior that you should be aware of if you want to use the Enable System Duplicate Detection option. CRM/Dataverse/CDS duplicate detection relies on an Asynchronous service job called the Matchcode Update job, which is not executed in real time. For this reason, any records that have been recently (for example, the last couple of minutes) added or updated in the system, will not have a matching code in the system until the Matchcode Update job kicks in next time, which usually happens every few minutes. Therefore, duplication detection would not take them into account. Due to the mentioned reason, we do not usually recommend relying on duplicate detection on large data load processes. A better option would be using the Upsert action, and selecting a combination of manually-selected matching fields. This is a more reliable solution since it performs a real-time duplicate check during the data load.
- Ignore Null-Valued Fields
-
The Ignore Null-Valued Fields option allows you to ignore any fields that have a null value. By ignoring a field, the null value will not be posted to the CRM/Dataverse/CDS server. This can help avoid the situation that you overwrite non-empty values with an empty value if your requirement dictates so.
- Ignore Unchanged Fields
-
The Ignore Unchanged Fields option allows you to ignore any fields that have not been changed in the target CRM/Dataverse/CDS system. This feature is useful when your CRM/Dataverse/CDS system has workflows or plugins to be fired when certain field value changes. With this option selected, the CRM/Dataverse/CDS destination component will check the target CRM/Dataverse/CDS system and compare each field to see if there are any changes for them. The component will only post the fields that have actual changes. All unchanged fields will be skipped and therefore, not posted to CRM/Dataverse/CDS. This component can prevent firing unnecessary CRM/Dataverse/CDS workflows or plugins.
Note: "Ignore Unchanged Fields" option does not apply to CRM/Dataverse/CDS partylist (activityparty) fields because partylist fields store complex values which are not always practical to compare. This does not have any negative impacts on your data integrity or anything in that regard, the only side effect is, all partylist fields will be posted to the CRM/Dataverse/CDS server regardless of whether there is a change or not.
- Change Flag Field(s)
-
The Change Flag Field(s) option can be enabled when the 'Ignore Unchanged Fields' option is selected. It is used in special cases to help track or tag where the last change of the record was initiated. For instance, if the source of your SSIS data flow is coming from your ERP system, you can have an input value for this field as "ERP" (or your actual ERP application name, such as "AX", "NAV"), we will only write to this field if there are any changes to other fields when the 'Ignore Unchanged Fields' option is selected. You can use a semi-colon (;) character as the delimiter to create a list of fields for this purpose.
- Remove Invalid Characters
-
When enabled, the Remove Invalid Characters option will remove any invalid characters from the input which can avoid an XML exception when the components try to construct the SOAP request to be sent to the CRM/Dataverse/CDS server. Those invalid characters are usually not accepted by the CRM/Dataverse/CDS server even posted.
- Batch Size
-
The Batch Size option allows you to specify how many records you would submit to the Dynamics 365 CE/CRM/Dataverse/CDS server at a time (each service call). The destination component will set a default batch size based on the version of your server. If the component has determined that the Bulk Data Load API is supported by your server, it will set the Batch Size to 100. Otherwise, it should default to 1. Using a batch size greater than 1 can help improve your data load performance, particularly if you are using a Dynamics 365 CE/CRM/Dataverse/CDS online connection or if you have a high network latency between your server and the computer from which you run the SSIS jobs or packages.
For most typical CRM/Dataverse/CDS entities, we generally recommend a Batch Size of 100 when working with Dynamics 365 on-premises installation. When working with Dataverse or Dynamics 365 CE/CRM/Dataverse/CDS online instances, you would use a Batch Size of 100 if xMultiple messages (CreateMultiple, UpdateMultiple, and DeleteMultiple) are supported by the entity. For all other entities that do not support xMultiple, it is recommended to use a batch size of 10 when working with an online instance. In the case that you are working with attachment entities (annotation, activititymimeattachment), it is generally recommended to use a relatively conservative batch size regardless of the deployment type, such as 10 or lower (1 would be the safest option to help avoid potential upload or server busy errors).
Note: When using a high Batch Size, you should consider increasing your connection manager's timeout setting to accommodate the extra time that is required for the server to process those requests in each batch.
- Use Homogeneous Batch Operation Messages (since v23.2.2)
-
The Use Homogeneous Batch Operation Messages option allows you to specify whether you want to leverage the newly introduced xMultiple batch request feature which is designed to increase data load throughput. While working on the destination component's configuration, we would automatically enable or disable the feature depending on whether the feature is supported by the chosen entity and action. It should be noted that xMultiple support is only available in the latest Dynamics 365 online instances, it might be supported in future on-premises releases after 2023.
Note: This option has a side-effect which should be taken into consideration if deciding to leverage the feature. When this option is used, if it happens that one of the records in the batch has failed due to any reasons, all records in the same batch will fail with the same error. This is due to the design at the platform level. We don't have a way to influence or control this behavior.
Note: When working with v23.2 or v23.2.1, there isn't an UI option for this configuration. Instead, xMultiple service calls are automatically enabled if they are supported by the entity while the Batch Size has been set to be greater than 20.
Note: In an early version of v23.2.2 release (v23.2.2.31101 to be exact), this option was named under "Use Heterogeneous Batch Operation Messages", which has been corrected since v23.2.2.32701.
- Enable Multithreaded Writing (since v9.0)
-
Since the v9.0 release, we added support for the Multi-threading feature, which allows you to perform multi-threading when writing data to CRM/Dataverse/CDS. To configure the Multi-threading feature, you can check the Enable Multithreaded Writing option in the CRM/Dataverse/CDS Destination Component. The default number is 16.
Note: This option supports a maximum number of 100 threads when writing to CRM/Dataverse/CDS. We generally recommend 20 or lower to avoid potential server errors. However, you can adjust these settings based on your environment in order to achieve the best performance.
Note: When this option is enabled, the record order may not be maintained from the upstream pipeline component.
- Send datetime values in UTC format
-
The Send datetime values in UTC format option indicates whether datetime values should be submitted to the CRM/Dataverse/CDS server in UTC format. This option will apply to all datetime fields when selected. When not selected, the datetime values are submitted based on the timezone setting of the connection or impersonation user.
- Execute Workflow Option
-
The Execute Workflow Option allows you to specify which CRM/Dataverse/CDS workflow or custom action you want to fire for the CRM/Dataverse/CDS records.
Note: In order for a CRM/Dataverse/CDS workflow to be shown in the list, the workflow has to be activated (or published) with the "As an on-demand process" option selected in CRM/Dataverse/CDS.
- Process Optimizations
-
These options are designed to turn off the server-side logic or processes such as workflows that might impact the writing performance, then enable them back after the writing process is complete. An information message will be displayed in the SSIS Execution Report to indicate the total number of disabled processes for the target entity, and another message will be reported when they are re-enabled.
- Bypass Business Logic Execution: You may select from the available dropdown options CustomAsync and CustomSync. Based on the enabled options, the synchronous and asynchronous plug-ins and real-time workflows will be disabled when the destination component performs the write operations to the platform. Using the option, the bypass behavior would only applied to the current service calls. This feature was introduced since v24.1.1 and has replaced the former BypassCustomPluginExecution feature made available from v21.2 and v24.1.
- Bypass Business Logic Execution StepIds: You may specify the step Id values (GUID) to have more granular control when bypassing custom business logic during the operation. This allows all other logic to continue as normal.
- Bypass Power Automate Flows (SuppressCallback RegistrationExpanderJob feature): When this option is enabled this would prevent designated Power Automate Flows that are set to trigger on data changes from running for the current service calls.
- Tentatively Disable Relevant Plugins (if any): When this option is enabled, all plugins related to the target entity will tentatively be disabled, regardless of the action registered. Plugins registered without a target entity will still remain in effect.
- Tentatively Disable Relevant Workflows (if any): When this option is enabled, all relevant workflows related to the target entity will tentatively be disabled.
- Tentatively Disable Entity Auditing (if enabled): When this option is enabled, it disables entity auditing for the target entity. This option involves publishing entity changes in order for it to work properly. As a result, any pending entity customizations in draft status before the job execution will be published during the process. Such changes will become permanent after the process.
- Refresh CRM Metadata Button
-
By clicking the "Refresh CRM Metadata" button, the component will retrieve the latest metadata from the CRM server and update each field. This feature works by performing the following three actions.
- Update any existing fields to the latest CRM metadata
- Add any new CRM fields that have recently been created in the CRM system
- Remove any CRM fields that have recently been deleted from the CRM system
After clicking this button, you will receive the following screen once the refresh is done.

This button can be also useful if you want to change the destination component's Connection Manager, or even the Destination Entity option without having to lose all existing mappings. In case you need to make such changes, you can first use the destination component's Advanced Editor window to change its Connection Manager, and/or the Destination Entity option accordingly, then re-open the destination component using its standard editor window, and click the "Refresh CRM Metadata" button, which should update the component properly.
- Map Unmapped Fields Button
-
By clicking this button, the component will map any unmapped CRM/Dataverse/CDS fields by matching their names with the input columns from upstream components. This is useful when your source component has recently added more columns, in which case you can use this button to automatically establish the association between input columns and unmapped CRM/Dataverse/CDS fields.
After clicking this button, you will receive the following message.

- Clear All Mappings Button
-
By clicking this button, the component will reset all your mappings in the destination component.
Columns Page
The Columns page of the CRM/Dataverse/CDS Destination Component allows you to map the columns from upstream components to CRM/Dataverse/CDS fields for the destination entity.
On the Columns page, you would see a grid that contains six columns as shown below.

- Input Column: You can select an input column from an upstream component for the corresponding CRM field.
- Destination CRM Field: The CRM field where you are writing data.
-
Text Lookup: This option is only available for CRM lookup fields. When this option is selected, the component can perform lookup based on the text value of the target entity. The text value is the value of the target entity's primary field. Depending on the software version that you are using, the component will have different behavior when duplicates are found in the lookup entity.
- In our v2.0 release, the Text Lookup feature will report an error when the text values of the target entity have duplicates (the values have to be unique).
- Between v3.0 and v4.1 releases (inclusively), uniqueness is not a requirement. When duplicates are encountered, the component will use the last record returned by the query against the target entity.
- From the v5.0 release, you can define how lookup duplicates are handled.
-
Data Type: This column indicates the type of value for the current CRM field in the CRM system. Typically, it is required to pass in the value using the format indicated in the Data Type column, but there are three exceptions.
- When working with the CRM lookup fields, if you are using the Text Lookup feature, you would pass in a text (string) value as the input although the field's Data Type is uniqueidentifier.
- CRM lookup type field (which usually ends with type or typecode such as owneridtype, objecttypecode, etc.) can take either integer values or string values, although its Data Type is int, when SOAP 2011 service endpoint is used. When working with SOAP 2007 or 2006 service endpoint, you must pass in the entity's type code in integer format.
- CRM OptionSet (or picklist) field can also take either integer values or string values, although its Data Type is int.
- Create: This column should only appear when the Upsert action is used. It indicates whether the field is applicable to a Create request for an Upsert action. When the field is not applicable to a Create request, the input value of this field will be ignored when we post the Create request to the CRM server.
- Update: This column should also only appear when the Upsert action is used. It indicates whether the field is applicable to an Update request for an Upsert action. When the field is not applicable to an Update request, the input value of this field will be ignored when we post the Update request to the CRM server.
- Unmap: This column can be used to unmap the field from the upstream input column, or otherwise it can be used to map the field to an upstream input column by matching its name if the field is not currently mapped.
When the Upsert action is selected on the General page, and the Upsert Matching Criteria option has been chosen as "Manually Specify", you will see a checkbox for each field listed in the grid. You may select one or more fields so their value(s) are used as matching criteria.

When the Upsert action is selected on the General page, you will see two more columns in the column mapping grid called Create and Update, they have a value of either Yes or No. What they indicate is whether the corresponding field is applicable to the specified action. When the field is not applicable to a particular action, the value for the field might be discarded before writing to the CRM/Dataverse/CDS. For instance, if the field is not applicable for Create, then the value will be ignored when the Upsert action tries to create a new CRM/Dataverse/CDS record. Likewise, if the field is not applicable for Update, the value will be ignored when the Upsert action tries to update existing CRM/Dataverse/CDS record(s). Note that this is a feature added in v1.1 SR1, so if you are using an earlier version of the toolkit, you may not see those two columns.
Note: To maximize the component's performance, it is not advised to select too many fields for the matching purpose.
Note: You should consider adding custom indexes to those manually specified matching fields that you have selected in the CRM/Dataverse/CDS database to improve the performance of the matching query.
Working with Text Lookup Feature
The Text Lookup feature allows you to perform lookup based on the text values of the target entity. To configure the Text Lookup feature, you click the ellipse button in the Text Lookup column which is available on the CRM/Dataverse/CDS destination component's mapping page. You will be presented with the following screen.

There are three options that you can choose to define how the lookup is performed.
- Do Not Use Text Lookup: This is the default option. When selected, you have to provide primary key values in GUID format as input for the lookup field.
- Use Primary Field (All): Using this option, the lookup will be performed based on the primary field(s) of the target entity/entities. In other words, the input of the lookup field should be the text values of the primary field for the target entity/entities. From a customization perspective, every CRM/Dataverse/CDS entity has a primary field. For instance, the account entity's primary field is name, the contact entity's primary field is fullname, and so on. So in the case when the lookup field is targeting the account entity, you can provide a text value of "ABC Company" as the input, the component will perform a search by looking up "ABC Company" from the account entity and convert it into GUID as the input value for the lookup field.
-
Choose Target Field(s): Using this option, you can specifically choose which text field should be used for the lookup purpose. When you choose this option, you will be presented with a list of the target entities for the lookup field, and you can choose to use a different lookup strategy for each target entity. In this list, you will be able to see the following options.
-
Lookup method: there are 5 options available defined below.
- Primary Field: The lookup will be performed based on the target entity's primary field. When you choose this option, any value in "Target Text Field" will be cleared.
- Manually Specify: You can choose whichever text field to be used for lookup purposes. Since the v10.0 release, we added support for a secondary lookup field when configuring the Text lookup feature, it allows you to specify an input column for the secondary lookup as needed. Note that the Manually Specify option is not available for the partylist fields, as the only possible way to do Text Lookup for the partylist field is the primary field.
- Alternate Key: You can choose to perform lookup using CRM/Dataverse/CDS Alternate Key for the specific entity. This option provides the capability to look up one or two fields as defined by the Alternate Key selected. In the case that the Alternate Key is defined by two CRM/Dataverse/CDS fields in the lookup entity, the input value passed to the lookup field will be used for the first field of the Alternate Key setup, and you will need to specify an input for the secondary key field, as shown below. Note that Alternate Key is a feature introduced in CRM 2015 Update 1, which is not available in the previous CRM/Dataverse/CDS version.

- <Opt Out - Input is GUID>: When chosen, the component will not perform text lookup for this particular target entity. In this case, a GUID input (or an empty value) will be provided for the concerned lookup entity. This option is particularly useful for the migration of partylist fields. If that is the case, you may want to do Text Lookup for systemuser entity, but not the other entities such as account, contact, and lead, in which case, you will be providing the GUID input for those lookup entities.
- <Nullify Input Values>(since v10.0): When chosen, the component will not perform lookup for this particular target entity. The value will be skipped for this particular lookup entity.
- Target text/integer field: This column allows you to specify which text/integer field will be used for the lookup purpose from the lookup entity. In the case the lookup method is chosen as Alternate Key, this is where you choose the Alternate Key that's defined in CRM/Dataverse/CDS.
- Write NULL on empty values(s) (since v10.1): When chosen, in the case that you only have one lookup field specified, the component will pass NULL value to the lookup field without performing a lookup when the input value is empty or NULL. In the case that you have two lookup fields specified (secondary lookup field is involved), the component will perform lookup only if one of the inputs is not empty or not NULL; if both inputs are empty or NULL, the component will pass NULL value to the lookup field without performing a lookup.
- Exclude inactive: When chosen, the component will exclude any inactive records from being used for the lookup purpose.
- Smart Name Match: When chosen, the lookup operation will match person names that have been written in a typical writing format such as (Firstname Lastname and Lastname, Firstname).
- Optional default value (if no match): When specified, the component will use this default value to perform the lookup should the input value lookup fail. This can be useful in some special scenarios, for instance, if you try to migrate the account entity with the ownerid field being set up to use the text lookup feature, and you, however, don't plan to migrate all systemuser records to the new CRM/Dataverse/CDS system (either those users have left the organization or they are no longer using CRM/Dataverse/CDS system). For those migrated users, the text lookup works fine. For those users that were not migrated, the text lookup feature will fail, in which case you can set a default value here (the user's fullname) so the component will default to the user-specified when the lookup of the primary input value has failed.
Note that if v9.2 or an earlier version is used, when the input value for the lookup field is empty (or NULL), text lookup will not be performed. Therefore, the optional default value will not be used in the case that the input value is empty. Since the v10.0 release, we changed this behavior so that we are going to do an actual lookup to find the records that have an empty (or NULL) value in the lookup entity.
Note that the optional default value can be "NULL" (case-insensitive with quotes removed), in which case it will perform a lookup using the input value, then the string literal "NULL". If that still fails to find a match, the component will set the lookup field's value to the empty one (NULL).
Note that since the v8.0 release, the optional default value supports using SSIS variables. When doing so, the variable should be in the format such as @[User::VariableName] or @[System::VariableName].
Note that since the v10.0 release, the Report Error on Duplicates option does not get fired when duplicates are happening to an empty (or NULL) lookup value.
-
Lookup method: there are 5 options available defined below.
In addition to the above options, the Text Lookup feature also offers the following advanced options.
- Ignore case: When chosen, the Text Lookup will perform a case-insensitive lookup. For instance, "ABC Company" will be treated the same as "abc company".
- Ignore Diacritics/Accents: When chosen, the Text Lookup will not take any diacritics within a string into consideration.
- Ignore Leading Whitespace: When enabled, the lookup operation will ignore any leading whitespace characters for lookup matching. This option is only applicable when it is using the Full Cache setting discussed below.
- Ignore Trailing Whitespace: When enabled, the lookup operation will ignore any trailing whitespace characters for lookup matching. This option is only applicable when it is using the Full Cache setting discussed below.
- Report error on duplicates: When chosen, the Text Lookup feature will report an error when a duplicate is encountered at the time the lookup cache is populated.
- Skip record if lookup fails: When enabled, the Text Lookup feature will skip the row when the lookup fails. Note that when this option is enabled, the skipped rows will not be sent to either the Default Output or the Error Output of the destination component.
-
Cache Strategy: You can choose from one of the two options:
- Full Cache: When chosen, the component will populate a full cache of all records from the lookup entity before starting to write to the target CRM/Dataverse/CDS system. This is the preferred option when the number of records in lookup entity is small. This option is the default mode when v4.1 or an earlier version is used.
- Partial Cache: When chosen, the component will gradually build up lookup cache as the data load progresses. This is the preferred option when the number of records in lookup entity is significantly large. For instance, if you have more than a few hundred thousand records in lookup entity, and you are only processing a few hundred records for your primary entity, Partial Cache mode would provide better performance.
Working with Option Value Mapping Feature
To configure the Option Value Mapping feature, you click the ellipse button in the OptionSet column which is available on the CRM/Dataverse/CDS destination component's mapping page. You will be presented with the following screen.
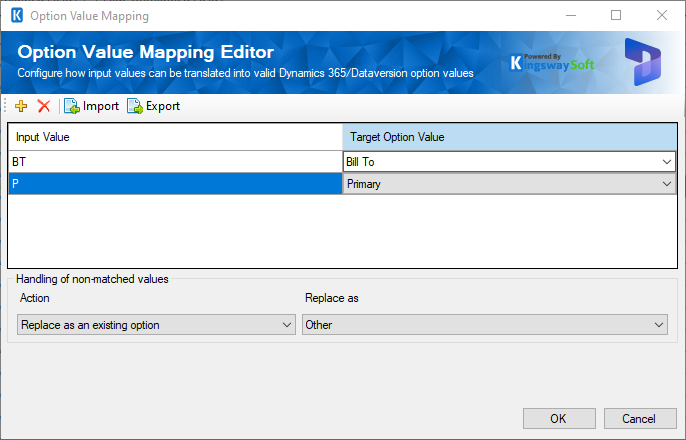
The top part of this window contains a grid that can be used to enter mapping values through four toolbar buttons. The first two buttons allow you to add or delete a mapping entry. The Import button allows you to import from a mapping that you previously saved or exported. The Export button allows you to export all mapping values in the grid to a .xml file so that edits can be made using a different tool that you feel more comfortable working with.
- Input Value
-
You can specify the value that an input needs to be translated.
- Target Option Value
-
The option values available in the Option field that can be chosen.
- Handling of non-matched values
-
The second part of the window is where you specify how to handle non-matched values. There are four options available:
- Create option
-
When no match is found for a particular input value, this option allows you to create a new option using the input value for the specified CRM/Dataverse/CDS option field. You could choose an Input column for the label from the drop-down while Create option is chosen.
- Replace as an existing option
-
When no match is found, an existing option value available in the CRM/Dataverse/CDS instance can be used as the default replacement value.
- Set an empty (NULL)
-
When no match is found, it would be set as empty (NULL).
- Raise an error
-
This option allows you to throw an exception that fails the component entirely when no match is found for a particular input value.
Working with principleobjectaccess Entity
To write to principalobjectaccess (POA) entity, you can use the following four actions.
- Create: A GrantAccess message that shares the CRM/Dataverse/CDS record with the intended team or system user.
- Update: A ModifyAccess message that modifies the sharing of the concerned CRM/Dataverse/CDS record.
- Delete: A RevokeAccess message that un-shares the CRM/Dataverse/CDS record with the intended team or system user.
- Upsert (since v9.2): The combination of Create and Update actions. It modifies the sharing of the concerned CRM/Dataverse/CDS record if matching can be found, otherwise, it shares the CRM/Dataverse/CDS record with the intended team or system user.
.png)
When writing data to a POA entity, you need to provide the following values:
- accessrightsmask: Access Rights Mask can be an integer value added up by any combination of the following numbers.
Read = 1
Write = 2
Append = 4
AppendTo = 16
Create = 32
Delete = 65536
Share = 262144
Assign = 524288
accessrightsmask is not needed for Delete (RevokeAccess) action, therefore the field is not available for the Delete action. - objectid: The CRM/Dataverse/CDS record's ID that you want to share or un-share.
- objecttypecode: The CRM/Dataverse/CDS record's typecode. If the SOAP2011 endpoint is used, you can use the entity's name.
- principleid: ID of the systemuser or team that you would like to share or unshare the CRM/Dataverse/CDS record with.
- principletypecode: Typecode of above the principleid. It should be either 8 (systemuser) or 9 (team). If the SOAP2011 endpoint is used, you can use the entity's name, which would be either systemuser or team.
Working with accessteammember Entity
To support the CRM Access Team feature, which was introduced in CRM 2013, we designed a virtual CRM entity called accessteammember, which allows the following two actions in the CRM/Dataverse/CDS destination component.
- Create: add a user to a CRM/Dataverse/CDS record's access team
- Delete: delete a user from a CRM/Dataverse/CDS record's access team
After you have selected the accessteammember entity, you would need to provide input for the following 4 fields.
- recordid: the CRM/Dataverse/CDS record's ID (in GUID) that you try to add (or remove) a user to (or from) its access team
- recordidtype: the record's entity name
- systemuserid: the CRM/Dataverse/CDS user you are trying to add (or remove) to (or from) the access team
- teamtemplateid: the access team template's primary key
Note: accessteammember is not a real CRM entity, it is not supported by CRM 2011 or earlier.
Error Handling Page
The Error Handling page allows you to specify how errors should be handled when they happen.

There are three options available that you can choose for the component's error handling:
- Fail on error
- Redirect rows to error output
- Ignore error
When the Redirect rows to error output option is selected, the error handling behavior might be different depending on the version of our software you are using.
- If you are using v5.0 or a later version, it will only redirect the rows that have failed to the error output (the successful ones will be directed to the Default Output of the destination component which is a new output in v5.0).
- If you are using v4.1 or an earlier version, it will redirect all rows to the error output including those that have succeeded and those that have failed. In case you need to further process CRM records after the destination component (such as logging CRM/Dataverse/CDS records to a different system, or writing to a different CRM/Dataverse/CDS entity using a subset of available fields) when using v4.1 or an earlier version, you must choose the "Redirect rows to error output" as the Error Handling option. Then attach a Conditional Split component to the CRM destination component. In the Conditional Split component, evaluate the ErrorCode column (an output field added by the CRM/Dataverse/CDS destination component) and check to see whether it has actually erred out. The Conditional Split should typically have two output branches, one is ErrorCode == -1, which is the success path, and the other one is ErrorCode != -1, which is the failure path indicating that an error has occurred when writing to the CRM/Dataverse/CDS.
In the error output, you can see the following columns:
- ID (version 4.1 or earlier): Contains the newly created CRM/Dataverse/CDS record's ID, which you can use to write to log or further process using additional data flow components. Note that this column has been moved to the Default Output of the destination component in v5.0 which has a new name called CrmRecordId.
- ErrorCode: Contains the error code that is reported by the CRM/Dataverse/CDS server or the component itself
- ErrorColumn: Contains the name of the column that is causing the error. Note that this column is not always populated
- CrmErrorMessage: Contains the error message that is reported by the CRM/Dataverse/CDS server or the component itself
Note: Use extra caution when selecting the Ignore error option, since the component will remain silent for any errors that have occurred.
In the Error Handling page, some options can be used to enable or disable the following output fields for the destination component's Default Output.
- CrmRecordId: Contains the newly created CRM/Dataverse/CDS record's ID, which you can use to write to log or further process using additional data flow components.
- IsNew: Contains value to indicate whether it is a newly created CRM/Dataverse/CDS record or an existing one. This is useful when you use the Upsert action.
- NoChangesRequired (since 9.1): Contains True or False value to indicate if changes are required. Returns True when there are no changes detected in the incoming record when compared to what’s in CRM/Dataverse/CDS. Otherwise, if there are changes detected, then it returns False. Note that this field is designed to work with the "Ignore Unchanged Fields" option - you need to have the option enabled in the destination component in order for the field to produce meaningful values.
Note: If you don't plan to use any of those fields for any further processing, it is generally recommended to turn them off, so you don't get any warning from SSIS by complaining that those fields are never used, and it should also provide slightly better performance by doing so.
In addition to the above settings, the Error Handling page also offers the following Additional Outputs option since our v8.0 release.
The "Skipped Rows" output can be useful when the Text Lookup is set up to Skip Records if Lookup Fails or the destination component’s Handling of Multiple Matches option is set to Ignore or the error-handling mechanism is chosen as “Ignore error” in the Error Handling page.