Using the Firestore Destination Component
The Firestore Destination Component is an SSIS data flow pipeline component that can be used to write data from an upstream SSIS Component to a Firestore instance.
The component includes the following five pages to configure how you want to write data:
- General
- Document Designer
- Columns
- Error Handling
General Page
The General page of the Firestore Destination Component allows you to specify the general settings of the component.
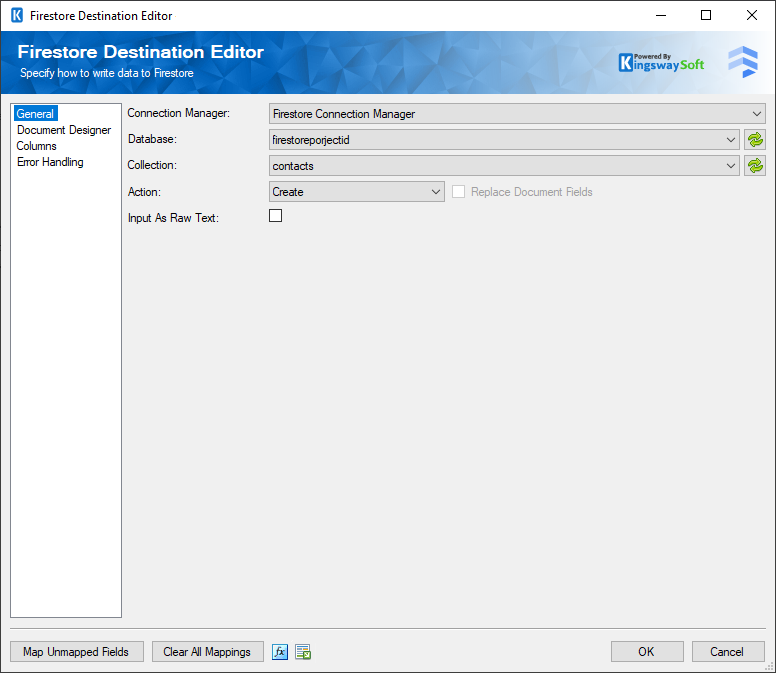
- Connection Manager
-
The Firestore Destination Component requires a connection in order to connect to a Firestore instance. The Connection Manager drop-down will show a list of all Firestore connection managers that are available to your current SSIS package.
- Database
-
This option lists all the available Databases in the Firestore instance. After selecting the Database you wish to read from, the Collection drop-down will be populated with the available Collections in the selected Database.
- Collection
-
This option lists all the Collections available in the selected Database.
- Action
-
There are four different actions in order to write items to a Firestore instance. Available actions are:
- Create: Creates a new item in a Firestore instance.
- Upsert: Updates any existing item(s) in a Firestore instance if a match can be found, otherwise create a new record with the information from the upstream pipeline components.
- Replace: Replaces an existing item in a Firestore instance with the information from the upstream pipeline components.
- Delete: Deletes an existing item in a Firestore instance.
- Input As Raw Text
-
Select this option to specify that the input would be raw text.
-
- Batch Write (Available for Update, Upsert and Delete actions)
-
Select this option to specify that batch mode be used.
-
- Batch Size (Available for Update, Upsert and Delete actions)
-
Specify the batch size.
-
- Batch Write Labels (Available for Update, Upsert and Delete actions)
-
Specify the batch write labels.
- Expression fx Icon
-
Click the blue fx icon to launch SSIS Expression Editor to enable dynamic updates of the property at run time.
- Generate Documentation Icon
-
Click the Generate Documentation icon to generate a Word document that describes the component's metadata including relevant mapping, and so on.
Document Designer Page
The Document Designer page allows you to build the design of the document you are trying to write to or import the design from an existing document.
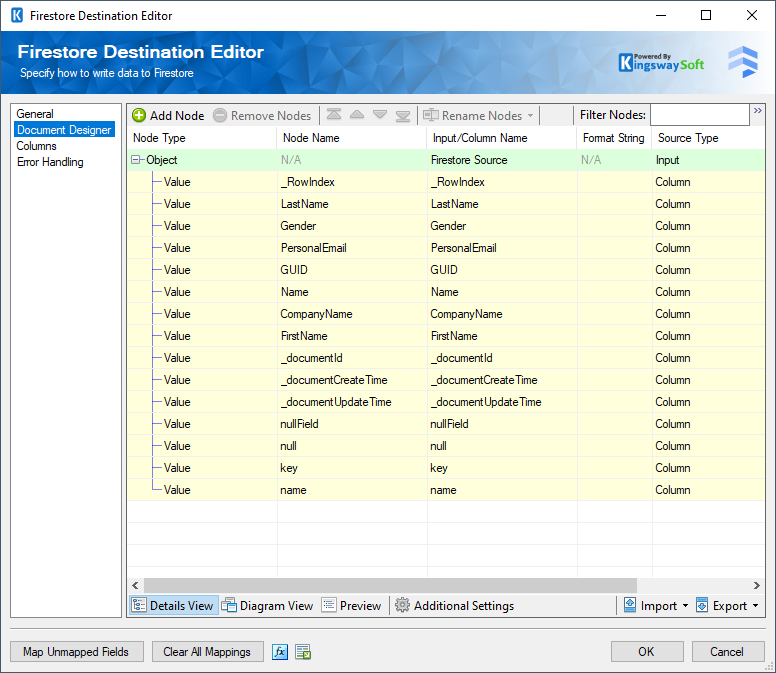
The Document Designer includes the following four tabs:
- Details View
- Diagram View
- Preview
- Additional Settings
In the Details View tab, the top part of the page is used to manually configure the nodes in the design:
- Add Node: This button will add a new node to your Document design.
- Remove Nodes: This button will remove a node from your Document design.
- Direction buttons: These buttons can be used to rearrange the position of the nodes.
- Rename Nodes: This option allows you to specify how the node name should be represented.
-
- Use Qualified Names: When this option is selected, the output/column name will be set to the full qualified node name based on the node location in the document.
- Use Short Names: When this option is selected, the output/column name will be set to the given Node Name directly.
-
Filter Columns: This option allows you to show or hide certain Columns in the grid.
- Show Basic Columns: When this option is selected, only basic columns will be shown in the grid.
- Show All Columns: When this option is selected, all available columns will be shown in the grid.
- Filter Nodes: This option allows you to filter the list of nodes shown in the grid by typing a keyword in the textbox.
The Details View grid consists of:
-
Node Type: This option allows you to specify the type of the Node in your document design, There are four options available:
- Array.
- Object
- Value
- Raw: This type can be used when trying to write JSON data under a node exactly as it is in the document.
- Node Name: The Name of the Node in the document.
- Input/Column Name: The name that will be used for the node when writing to the document.
- Is Repeated: This option allows you to specify if a node is repeated within a document. (Available when Show All Columns is selected)
- Format String: This option allows you to specify the target output format for a string when converting datetime/number values to a string. It follows the same .Net formatting function found at this link (Available when Show All Columns is selected).
- Source type: The type of the input for a node such as a dedicated Input, Variable, or Column, depending on the Node Type.
- Node-Write Settings: This option allows you to specify the settings of each node such as the datatype or the Variable Name based on the selected Source Type.
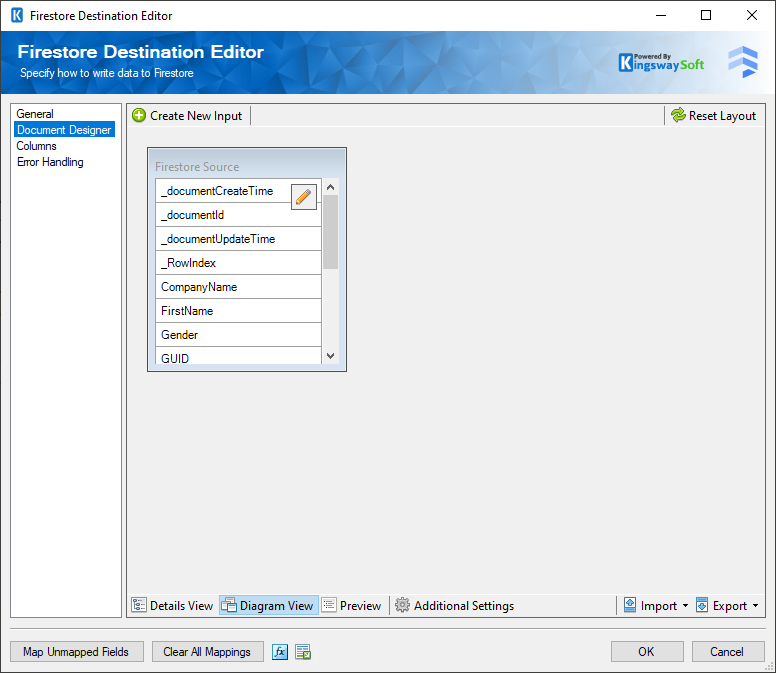
In the Diagram View tab, you would be able to view the document design as a diagram where you can link different inputs with each other in order to create the hierarchy of your document and establish relationships between the different inputs:
-
- Create New Input
-
This option allows you to create a new Input and link it to an existing input if required based on the intended document design.
- Delete Selected Input
-
This option allows you to remove existing Inputs from the diagram
- Reset Layout
-
This option allows you to rest the layout of the diagram which would reorganize the location of each input.
In the Preview tab, the component will show a sample of the document which will be created with test values.
In the Additional Settings tab, you will find the following options:
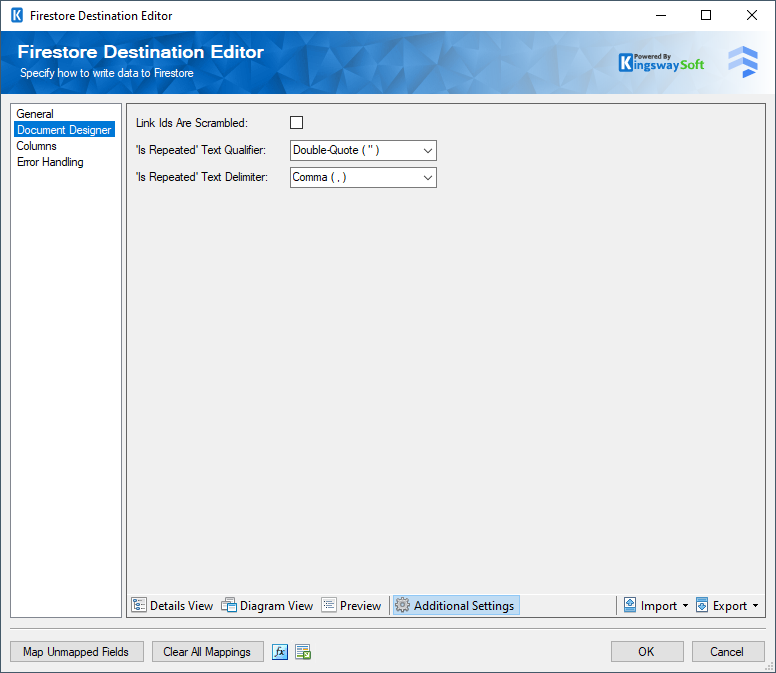
- Link IDs Are Scrambled: This option specifies whether the Link IDs are scrambled between the inputs. When the option is checked, it indicates that Link IDs can come from the source system in random orders, in which case our software will perform an in-memory matching and joining, which could substantially impact the writing performance. If the incoming Link IDs are not scrambled (for instance, those IDs are properly sorted in ascending order within each input), this option can be unchecked, which will emit some much greater merge/writing performance, and it could also avoid out-of-memory exceptions when working with a large data set if disabled.
-
'Is Repeated' Text Qualifier: This option allows you to specify the
Text Qualifier used in a document when the
Is Repeated property is set to
True for one or more nodes. There are four options available:
- Double-quote(“)
- Single-quote (‘)
- Tick (`)
- None
-
'Is Repeated' Text Delimiter: This option allows you to specify the
Text Delimiter used in a document when the
Is Repeated property is set to
True for one or more nodes. There are seven options available:
- Newline (\n)
- Carriage Return (\r)
- Semicolon (;)
- Colon (:)
- Comma (,)
- Tab (\t)
- Vertical Bar (|)
- Import
-
This option allows you to import the design of your document from one of the following five sources:
- Designer Settings: Import the design from an existing .designer.settings file.
- Input (Reset Design): Create the design based on the input columns for the upstream components.
- Document (Firestore): Import the design based on the retrieved document from the connection manager.
- JSON (Local File): Import the design based on a JSON file on your local file system.
- JSON Schema (Local File): Import the design based on a JSON Schema file on your local file system.
- Firestore Item Importer
-
When selecting the Item (Firestore) Import option, the Firestore Item Importer window will open which allows you to specify a query that will set the design of the Destination Component based on the retrieved document.
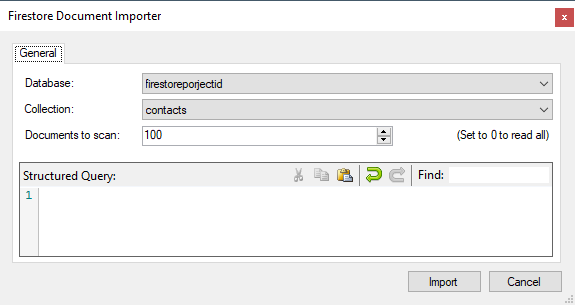
- Documents to scan: This option allows you to specify the maximum number of retrieved documents that will be used to set the design of the Destination Component. Setting this option to 0 will read all the retrieved documents.
- Export
-
Designer Settings: This option allows you to export the current document design to a .designer.settings file which can be used later to import the same design into a different component.
Columns Page
The Columns Page of the Firestore Destination Component allows you to map the columns from upstream components to the defined nodes for the designed document.
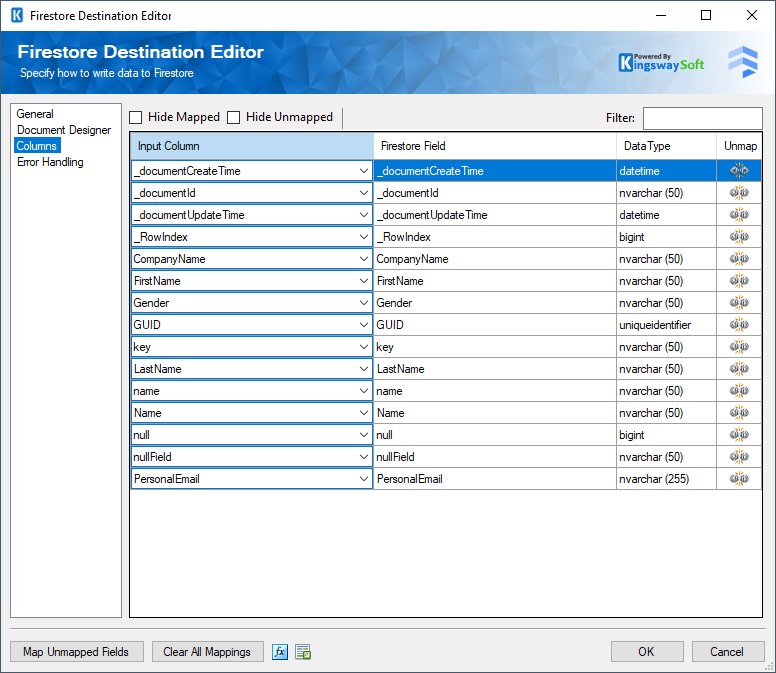
- Input Column: Select an Input Column from an upstream component.
- Firestore Field: This is the field you are writing data to
- Data Type: This column indicates the type of value for the current field.
- Unmap: This column can be used to unmap the field from the upstream input column, or otherwise it can be used to map the field to an upstream input column by matching its name if the field is not currently mapped.
Error Handling Page
The Error Handling page allows you to specify how errors should be handled when they happen.
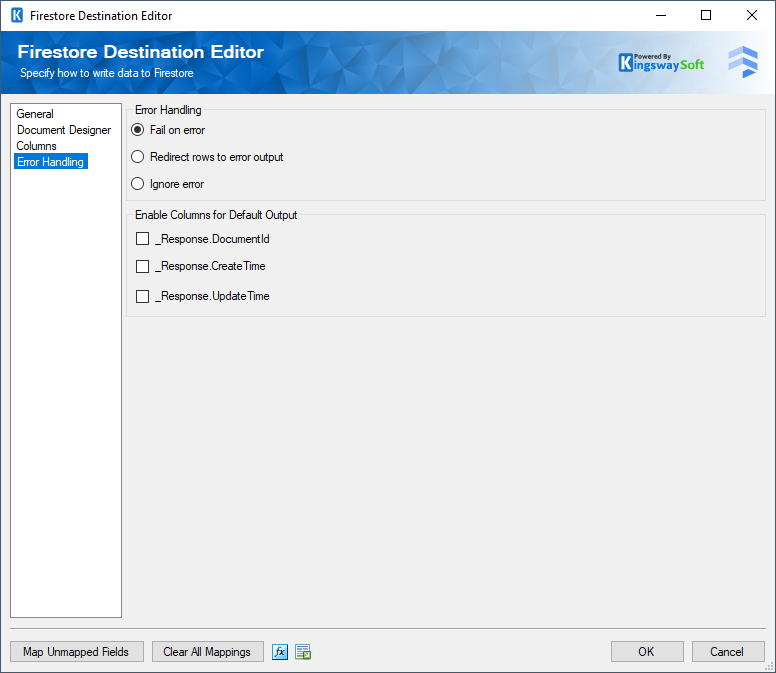
There are three options available.
- Fail on error
- Redirect rows to error output
- Ignore error
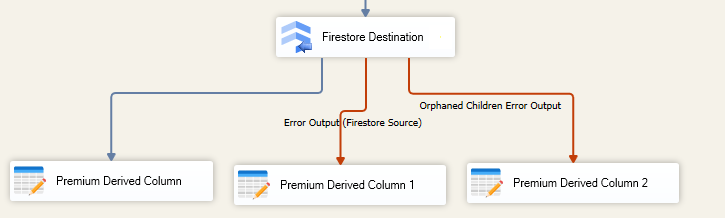
When the Redirect rows to error output option is selected, rows that failed to write to the target Firestore instance will be redirected to the 'Error Output({PrimaryInputName})' output of the Destination Component; rows from the Child Input that failed to find the parent records will be redirected to the 'Orphaned Children Error Output' output of the Destination Component. As indicated in the screenshot below, the blue output connection represents rows that were successfully written, and the red 'Error Output{PrimaryInputName}' and 'Orphaned Children Error Output' connection represents erroneous rows.
- Error Output({PrimaryInputName})
- ErrorCode: Contains the error code that is reported by the Firestore instance or the component itself
- ErrorColumn: Contains the name of the column that is causing the error. Note that this column is not always populated
- ErrorMessage: Contains the error message that is reported by the Firestore instance or the component itself
- Orphaned Children Error Output
- ErrorCode: Contains the error code that is reported by the Firestore instance or the component itself from the Child Inputs
- ErrorColumn: Contains the name of the column that is causing the error from the Child Inputs. Note that this column is not always populated
- Input Name: Contains the name of the Child Input that is having an issue.
- Column Name: Contains the name of the column that is having an issue in the specific Child Input.
- Column Value: Contains the value of the column that is having an issue in the specific Child Input.
- Parent Input Name: Contains the Parent Input name of the specific Child Input.
- Parent Column Name: Contains the name of the column that is having an issue in the specific Parent Input.
Note: Use extra caution when selecting the Ignore error option, since the component will remain silent for any errors that have occurred.
On the Error Handling page, there is also an option that can be used to enable or disable the output fields for the destination component default output.
Note: If you don't plan to use this field for any further processing it is recommended to disable it. This is so you don't get any warnings from SSIS indicating that the field is never used and it will also provide slightly better performance.