Using the Databricks Destination Component
The Databricks Destination component is an SSIS data flow pipeline component that can be used to write data to a Databricks instance. There are three pages of configuration:
- General
- Columns
- Error Handling
General Page
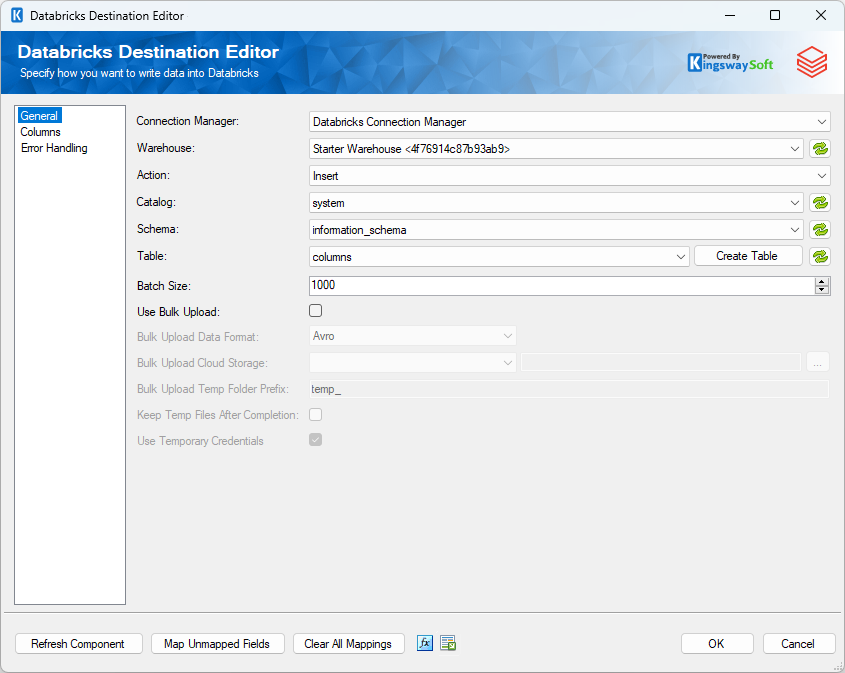
The General page of the Databricks Destination Component allows you to specify the general settings of the component.
- Connection Manager
-
The Databricks Source Component requires a Databricks connection manager.
- Warehouse
-
The Warehouse option is a drop-down list that allows you to pick one of the Databricks warehouses available in your Databricks instance.
- Action
The command you want to execute on the Table. Available actions include: -
- Insert: Add records to the Table
- Update: Update existing records in the Table
- Delete: Delete existing records from the Table
- Upsert: If the specified record exists in the Destination Table it is updated otherwise it is inserted.
- FullSync: Synchronize input data to the Destination Table. Full Sync action differs from Upsert action in the way that it can delete those records in the target system but not in the source system.
- Custom Command: Allows you to write your own database command. When the Custom Command action is selected you will notice a command text box and a tree view will appear. The tree view contains a list of Input Columns, SSIS Variables, and Database Tables from the selected Databricks Connection Manager. Selecting a table will expand it with its columns. You can drag and drop the items in the tree view to the command text box to help construct the command. During runtime, the command is executed for each record in the Input. Column and Variable values are properly parameterized and prepared for the database.
- Catalog
-
The Catalog drop-down menu displays a list of available catalogs in the Databricks instance defined in the Connection Manager. Selecting a catalog here will automatically populate the Schema drop-down list.
- Schema
-
The Schema drop-down menu displays a list of available Schemas in the previously selected Databricks catalog. Selecting a schema here will automatically populate the Table drop-down list.
- Table
-
The Destination Table drop-down menu displays a list of available tables from the schema specified in the previously selected catalog schema.
- Batch Size
-
The Batch Size option allows you to specify how many records you want to send to the target database server at a time. The default value is 1000
- Use Bulk Upload
-
Use Bulk Upload checkbox specifies whether you want to perform a bulk load operation into Databricks, the data is first uploaded to a temporary file on Databricks File System (DBFS) and from that temporary file, the data is loaded into the destination table.
-
- Batch Upload Data Format
-
The Bulk Upload Data Format lets you specify in which format would you like to perform the uploads. There are three options available:
- Avro
- CSV
- Parquet
-
- Bulk Upload Cloud Storage
-
The Bulk Upload Cloud Storage specifies which storage to use to stage the files in an external location. Once the Bulk Upload Cloud Storage is chosen, click on the ellipsis (…) button to select the path where the file would need to be generated
- Bulk Copy Temp Folder Prefix
-
This Bulk Copy Temp Folder Prefix option specifies the temporary folder name prefix for the staging files in the specified Bulk Copy cloud storage service.
-
- Keep Temp Files After Completion
-
This option can be enabled to keep the files from the stage location once the copy is done.
-
- Use Temporary Credentials
-
Use Temporary credentials uses short-lived, downscoped credentials to access cloud storage locations where table data is stored in Databricks. These credentials are employed to provide secure and time-limited access to data in cloud environments.
- Refresh Component Button
-
Clicking the Refresh Component button causes the component to retrieve the latest metadata and update each field to its most recent metadata.
- Map Unmapped Fields Button
-
By clicking this button, the component will try to map any unmapped attributes by matching their names with the input columns from upstream components.
- Clear All Mappings Button
-
By clicking this button, the component will reset (clear) all your mappings in the destination component.
- Expression fx Icon
-
Click the blue fx icon to launch SSIS Expression Editor to enable dynamic updates of the property at run time.
- Generate Documentation Icon
-
Click the Generate Documentation icon to generate a Word document that describes the component's metadata including relevant mapping, and so on.
Columns Page
The Columns page of the Databricks Destination Component allows you to map the columns from upstream components to fields of the specified Destination Table in the General Page. The Columns Page is not available when the selected action is Custom Command.
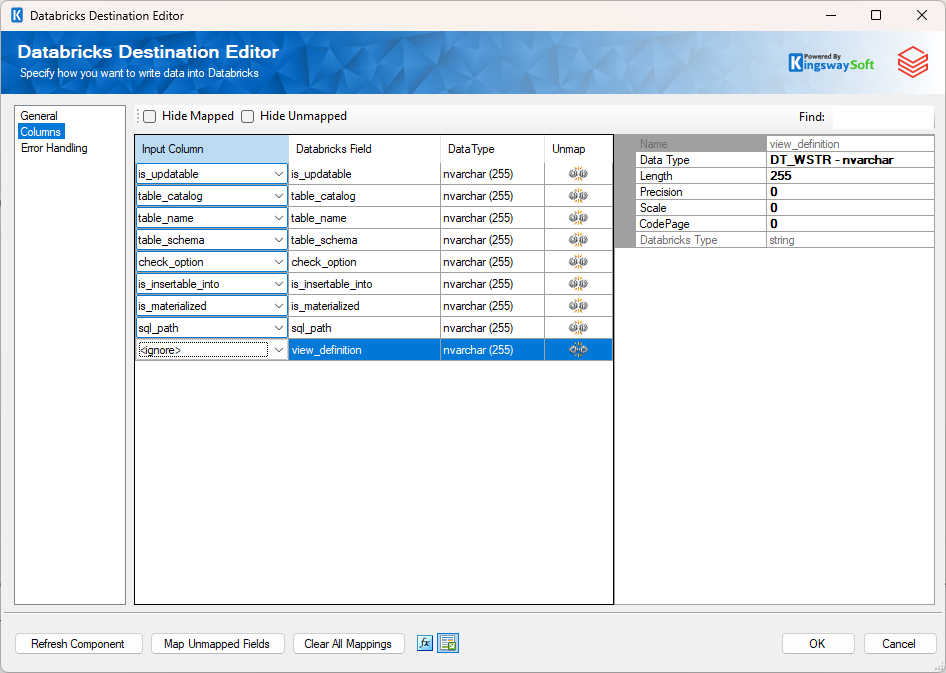
- Input Column: Select an Input Column from an upstream component here.
- Databricks Field: This is the field you are writing data to.
- Data Type: This column indicates the type of value for the current field.
- Unmap: This column can be used to unmap the field from the upstream input column, or otherwise it can be used to map the field to an upstream input column by matching its name if the field is not currently mapped.
Error Handling Page
The Error Handling page allows you to specify how errors should be handled when they happen.
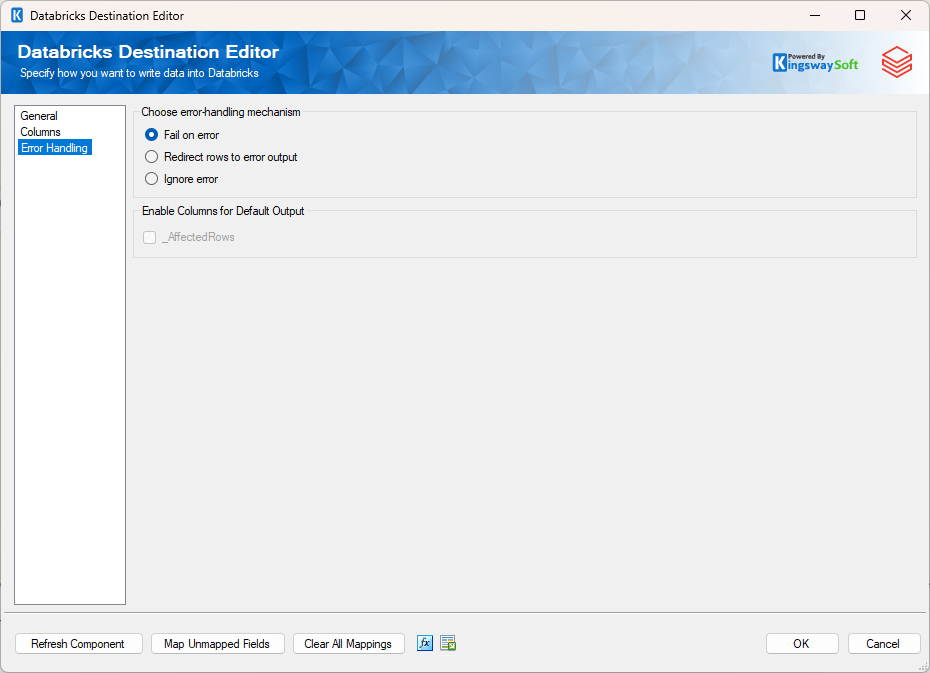
There are three options available.
- Fail on error
- Redirect rows to error output
- Ignore error
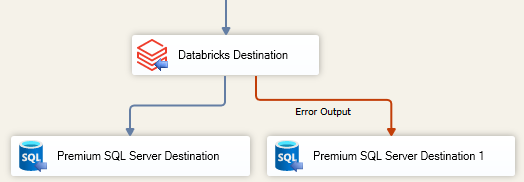
When the Redirect rows to error output option is selected, rows that failed to be sent will be redirected to the 'Error Output' output of the Transformation Component. As indicated in the screenshot below, the blue output connection represents rows that were successfully sent, and the red 'Error Output' connection represents erroneous rows. The 'ErrorMessage' output column found in the 'Error Output' may contain the error message that was reported by the server or the component itself.
Note: Use extra caution when selecting Ignore error option, since the component will remain silent for any errors that have occurred.
In the Error Handling page, there are also options that can be used to enable or disable the following output fields for the destination component's Default Output.
_AffectedRows: Reports the number of affected rows for the SQL script executed for each incoming row. This option is not available when the Bulk mode is used.